
Benchmarking Consumer AI on Residential Leases
TL;DR
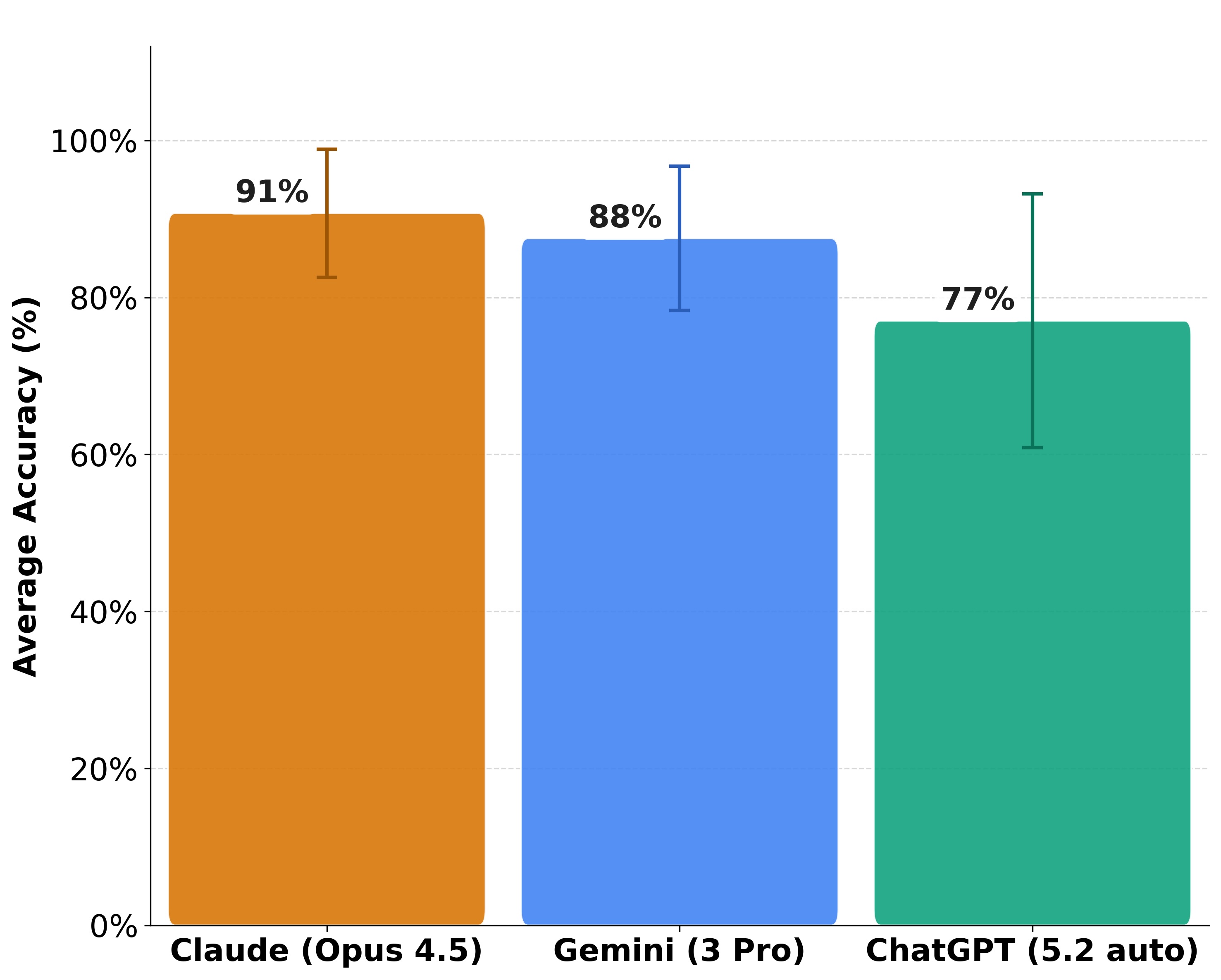
- We evaluated three AI chatbots: Claude Opus 4.5 led on accuracy (91%), followed by Gemini 3 Pro (88%) and ChatGPT 5.2 (77%)
- Consistent failures, included missing text, multi-hop reasoning errors, and hallucinated signatures
- Despite lower accuracy, Gemini was most practical for lease review due to its citation interface
Context
Recent surveys indicate that 56% of AI users have utilized chatbots for legal advice*. While benchmarks like LegalBench measure how foundation models handle raw legal logic, there is a gap in understanding how consumer-facing tools handle the parsing of real-world document files. We conducted a stress test comparing ChatGPT (GPT-5.2), Claude (Opus 4.5), and Gemini (3 Pro) on a common legal document: the residential lease.
Methodology
To ensure statistical significance and account for variability, we utilized the following protocol:
- Dataset: 30 PDF lease contracts generated from diverse templates to ensure layout variation.
- Controls: On 25% of documents, signature fields were intentionally left blank to test for hallucination.
- Volume: We ran 9 questions per document across 3 separate runs, totaling 810 distinct queries.
- Task Scope: Tasks ranged from simple extraction ("What is the rent?") to multi-step reasoning (calculating late fees) and visual reasoning (detecting checkboxes)
Results
In terms of raw accuracy across all questions, Claude Opus 4.5 performed best, though the margin between the top two models was small.
- Claude (Opus 4.5): 91% accuracy. It demonstrated the most consistent performance, topping the ranking on 6 out of 9 question types.
- Gemini (3 Pro): 88% accuracy. It performed slightly less consistently than Claude but outperformed ChatGPT significantly.
- ChatGPT (5.2): 77% accuracy. It performed the worst across 8 question types and showed the highest performance variance.
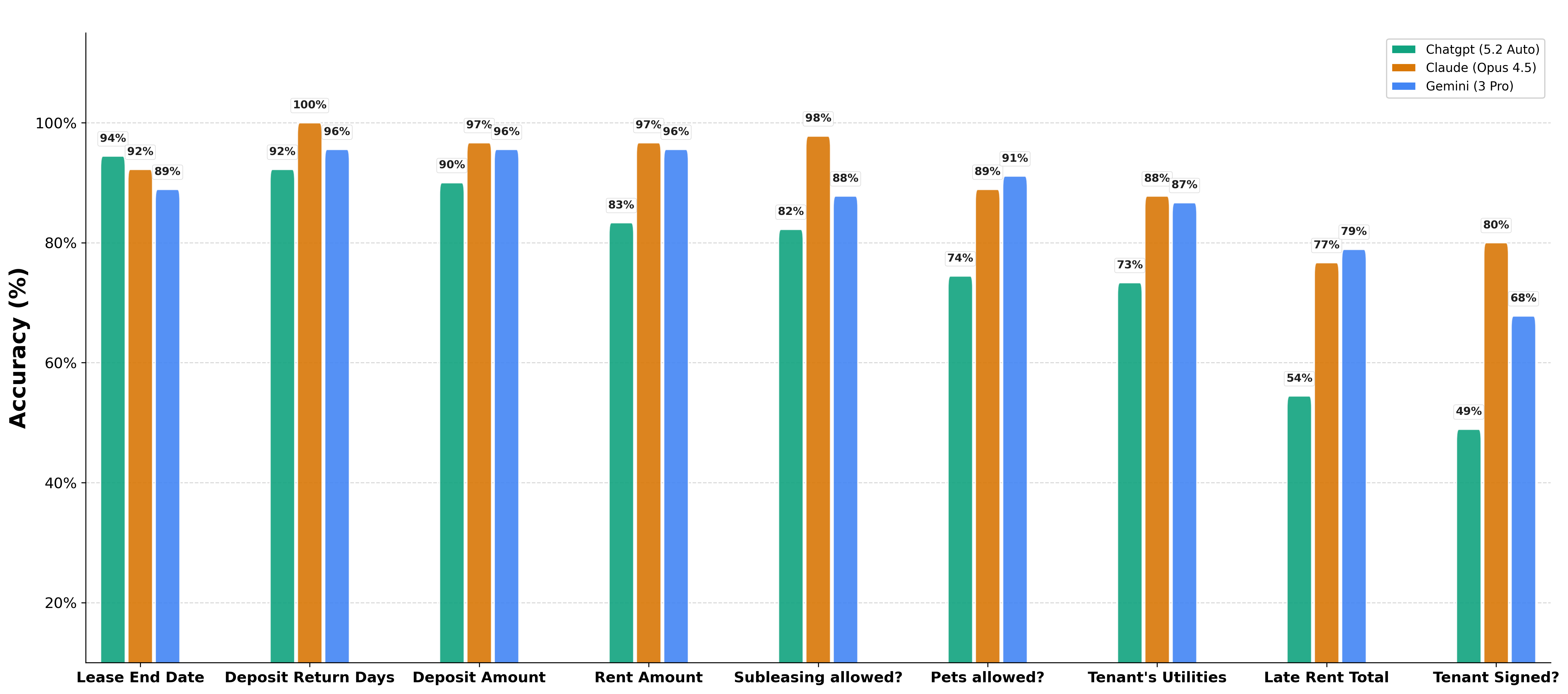
Failure Analysis
Broadly, all failures fell into one of two categories: Omissions (claiming data didn't exist when it did) and Incorrect Values (referencing a wrong value or hallucinating a logic). Specifically, we observed five distinct patterns of failure:
- Blindness: Failure to see the text filled into the template
- Concept Confusion: Swapping semantically similar terms, such as reporting the "security deposit" when asked for "monthly rent."
- Multi-hop reasoning: Failure to retrieve a value (rent), retrieve a policy (late fee %), and then perform a calculation.
- Reconciling Policy Default: Failure to infer that if a subleasing requires written permission, the default is that subleasing is prohibited.
- Visual Gaps: Failure to detect structural elements like signatures, checkmarks.
Some failures were intermittent – a model might fail a question on Run 1 but get it right on Run 2. To account for this stochastic behavior, all accuracy numbers reported above are averages from three separate runs. Below are examples with screenshots from the document.
- Blindness. ChatGPT 5.2 struggled to read text explicitly filled into standard forms. In one instance, when asked for a lease end date that was clearly typed as "January 1, 2027," the model claimed the field was "left blank"

- Multi-hop reasoning. When tasked with multi-step reasoning (finding a late fee policy + calculating the sum), models often invented policies. For example, ChatGPT 5.2 ignored a stated "10% of one month's rent" penalty and instead calculated a "10 dollars per day" fee, resulting in an incorrect total.

- Visual Gaps. Claude Opus 4.5 hallucinated a signature on a blank line, reasoning that because the document contained a date in the signature block, the tenant must have signed it.

The Verification Bottleneck
While raw accuracy is the primary metric for chatbot evaluation, operational efficiency in a professional workflow depends on verification. Since no chatbot achieved 100% accuracy, the ability for a human to verify the output is critical. We found significant differences in the UI regarding citations:
- Gemini: Offers the highest utility for review. It provides citation links that open the document and highlight the specific text used to generate the answer.
- ChatGPT: Provides reference links, but they generally open the document without pointing to specific clauses or pages, slowing down verification.
- Claude: Provided no citation UI.
Conclusion
For workflows involving contract review, the choice of tool depends on the balance between raw model intelligence and interface utility.
- Gemini 3 Pro is currently the most viable tool for reviewing legal documents. Despite a 3% lower accuracy rate than Claude (88% vs 91%), its citation interface allows for rapid verification of answers, which is essential given the error rates observed across all models.
- Claude Opus 4.5 demonstrates the strongest reasoning capabilities. However, the lack of a citation interface makes verifying its answers a manual, time-consuming process.
- ChatGPT 5.2 trails significantly in both accuracy (77%) and citation granularity